Friday 27th February, 2026
 by James Mead
by James Mead
Week 893
Week beginning 23rd February, 2026.
The week was a bit disrupted: I was travelling back from the Isle of Wight on Monday and off sick on Thursday morning, Chris L was off sick on Tuesday, and Chris R quite properly took Thursday off for his birthday - belated happy birthday, Chris! 🎂
Government Digital Service 🏷️
We’ve moved on from our work on the national applicability of documents on GOV.UK. Now we’re looking at what’s known as the topic taxonomy which on most pages provides the data for the breadcrumb links at the top the page and the “Explore the topic” links the bottom of the page. Some internal tooling suggests that a topic taxon which has more than 300 documents is regarded as “unhealthy”, but it doesn’t really help the user (typically a GDS content designer or information architect) fix the problem. It turns out there are many topic taxons which exceed this threshold.
To help us identify these “unhealthy” taxons and work out which to look at first, Chris L & Chris R have been using their PostgreSQL superpowers on a copy of the GOV.UK content store to construct a denormalized fact table suitable for import into a table view in Google Sheets.
I’ve written a scrappy Python script which takes a leaf taxon with approx 1,000 documents (i.e. the taxon is “unhealthy”) and uses the BERTopic package to group the documents into candidate clusters. BERTopic wraps up a bunch of machine-learning steps into a customizable workflow with sensible defaults:

I’ve only tweaked a couple of things so far. Firstly, I’ve configured the Count Vectorizer to ignore English stop words to avoid them ending up as suggested keywords for a cluster. Secondly, I’ve configured a Represenation Model which uses OpenAI’s gpt-4o-mini model to suggest human-friendly topic names using the keywords and a number of example documents from the cluster. The script outputs a CSV file suitable for uploading to Google Sheets which includes links to all the documents alongside the suggested topic name.
The results so far look promising, but I’m sure there’s a lot more work to do to build a genuinely useful prototype. Anyway, it feels good to be using problem-specific machine learning techniques rather than just chucking everything into an LLM and hoping for some half-sensible output.
Code Club 🤖
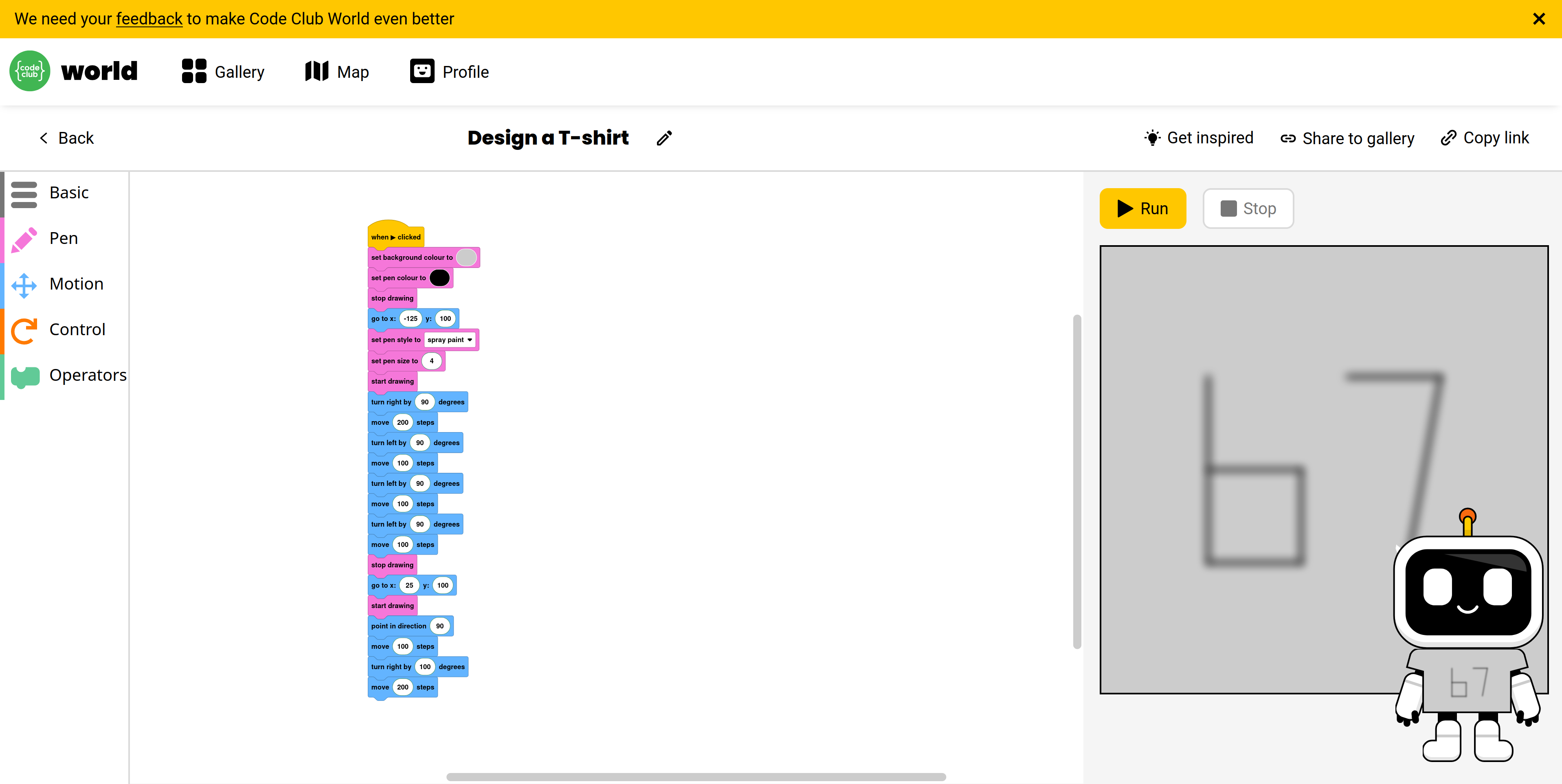
Chris R ran his Code Club again on Tuesday - he wrote this program on Code Club World, printed it out, and got some of the children to recreate it. It reminds me of typing in programs from magazines on a ZX-Spectrum in the 1980s! Also it’s great that he’s using an app which we built for the Raspberry Pi Foundation back in the days of the COVID-19 pandemic.
Miscellaneous 🧩
We’ve not had time for much else, but…
We’ve had various Biz Dev conversations about what we might do after our GDS contract ends at the end of March.
I removed a Google Group which we’d been using as a kind of catch-all email address - it was just catching a load of spam and cluttering up our company Trello board, so it feels good to have removed it.
Chris L is having a call to discuss a project which won a grant from the Goldsmiths’ Partnerships, Innovation & Impact Fund to run an event in the summer. The project is called: “Scaling cooperation: Working together for a fairer, more productive digital platform ecosystem in the new music economy” which is very relevant to Jam.
Anyway, that’s all for now.
Until next time.
– James
If you have any feedback on this article, please get in touch!
Historical comments can be found here.